I Tested Every Gemma 4 Model Locally on My MacBook — What Actually Works
Audio ASR in 3 languages, image understanding, full-stack app generation, coding, and agentic behavior -- all on a MacBook M4 Pro 24GB.

Your MacBook Has Ears Now… And Eyes, And Opinions — I ran every Gemma 4 model on 24GB of RAM so you don’t have to melt yours first.
Watch the video: Gemma 4 Benchmark on YouTube
TL;DR - The 30-Second Version
What: A comprehensive benchmark of all four Gemma 4 models (E2B, E4B, 26B-A4B, 31B) running locally on a MacBook M4 Pro with 24GB RAM.
Winner: Gemma 4 E4B — perfect audio ASR in 3 languages, solid image understanding, generates working full-stack React apps, and runs at 57 tok/s via Ollama.
Surprise: Gemma 4 E2B is blazing fast (95 tok/s) but chokes on audio and app generation. The 26B model is unusable at ~2 tok/s on 24GB.
Verdict: E4B 8.5/10 · E2B 7/10 · 26B 2/10 on 24GB
The Gemma 4 Family
Google dropped four Gemma 4 models and the local AI community immediately had one question: which ones actually run on consumer hardware?
| Model | Parameters | Architecture | Modalities | 24GB Viable? |
|---|---|---|---|---|
| Gemma 4 E2B | 2B | Dense | Text, Image, Audio | Yes |
| Gemma 4 E4B | 4B | Dense | Text, Image, Audio | Yes |
| Gemma 4 26B-A4B | 26B (4B active) | Mixture of Experts | Text, Image | Barely |
| Gemma 4 31B | 31B | Dense | Text, Image | No (needs ~20GB+ VRAM) |
The E2B and E4B are the stars of the local scene — both support text, image, and audio natively. The 26B MoE model technically loads but crawls. The 31B is out of reach for 24GB machines. I tested the first three extensively.
Speed Benchmarks: Tokens Per Second
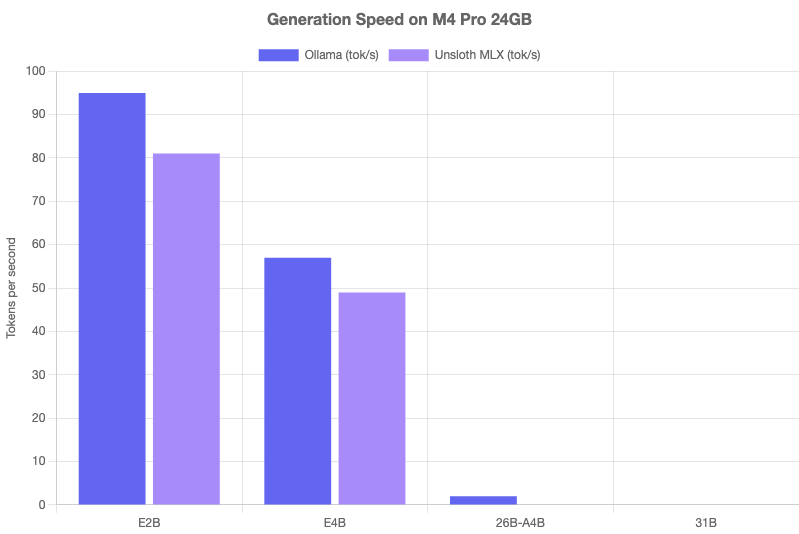
| Model | Ollama (tok/s) | MLX (tok/s) | Feel |
|---|---|---|---|
| E2B | 95 | 81 | Instant — faster than you can read |
| E4B | 57 | 49 | Smooth — comfortable for real-time use |
| 26B-A4B | ~2 | — | Unusable — constant swapping on 24GB |
Key takeaway: Ollama consistently outperformed MLX on these models. E2B at 95 tok/s is genuinely impressive for a multimodal model — it streams text faster than most people can read. E4B at 57 tok/s is comfortably usable for interactive work. The 26B-A4B MoE model technically loads, but with constant memory pressure and ~2 tok/s, it’s not practical on 24GB.
Audio ASR: 3 Languages, Native Speech Recognition
This is where things get interesting. E2B and E4B both accept raw audio input natively — no Whisper, no preprocessing. Just feed a WAV file and ask for a transcription. I tested three languages with very different scripts and phonetics.
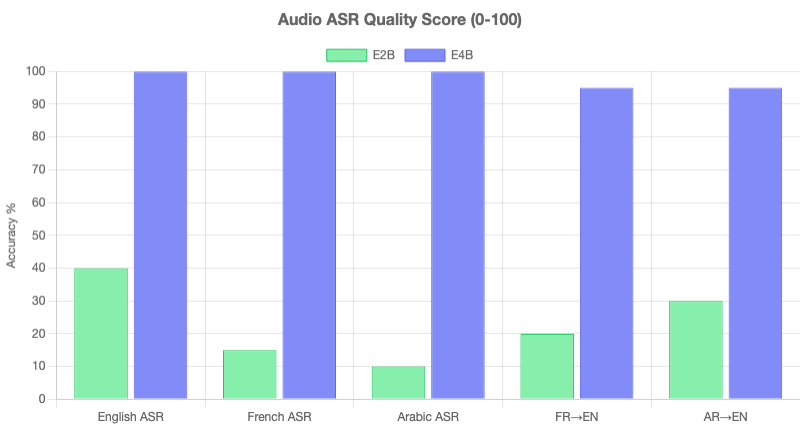
English
| Model | Result | Time | Accuracy |
|---|---|---|---|
| E4B | Perfect transcription | 1.0s | Excellent |
| E2B | Garbled, repeated fragments | 2.8s | Poor |
French
| Model | Result | Time | Accuracy |
|---|---|---|---|
| E4B | Perfect transcription | 1.6s | Excellent |
| E2B | Fragmented, missing words | 4.1s | Poor |
Arabic
| Model | Result | Time | Accuracy |
|---|---|---|---|
| E4B | Perfect transcription | 6.0s | Excellent |
| E2B | Garbled output | 6.0s | Poor |
Speech Translation (E4B Only)
E4B also handles cross-language speech translation natively. I asked it to translate the French and Arabic audio directly into English — no intermediate transcription step. It produced accurate, natural translations from raw audio. E2B could not manage this at all.
“The gap between E4B and E2B on audio is not subtle. E4B is a genuine local Whisper alternative. E2B is not.”
Image Understanding
All three models support image input. I tested with three photographs that exercise different capabilities: architectural detail, Japanese OCR + cultural context, and wildlife identification.
Thai Temple

E4B: Correctly identified the architectural style, described ornamental details, and recognized it as a Thai Buddhist temple. E2B: Provided a reasonable but shallower description. 26B: Gave the most detailed analysis but took over a minute to generate.
AI-Generated Tokyo Street + Japanese OCR

E4B: Identified the scene as likely AI-generated, read the Japanese text on signs, and provided translations. E2B: Described the scene correctly but struggled with OCR on the Japanese characters. 26B: Most accurate OCR but impractically slow.
Venice Seagull

E4B: Identified the bird species, described the Venetian backdrop, and noted behavioral details. E2B: Correct identification but minimal context. 26B: Rich description, painfully slow.
Image understanding verdict: All models are competent. E4B hits the sweet spot of quality versus speed. The 26B gives marginally better results but not enough to justify the wait.
Full-Stack App Generation
The acid test: can these models generate a complete, working React application in a single prompt? I asked each model to build a task manager with drag-and-drop, local storage persistence, and a polished UI.
| Model | Result | Lines | Compiles? | Runs? |
|---|---|---|---|---|
| E4B | Working React app with drag-and-drop, localStorage, clean UI | 155 | Yes | Yes |
| E2B | Incomplete, broken imports, would not compile | — | No | No |
| 26B | Timed out before completing generation | — | — | — |
E4B generated a production-quality 155-line React application that compiled and ran on the first attempt. It included proper state management, event handlers, and CSS styling. E2B produced fragments that wouldn’t compile. The 26B timed out.
Try the E4B-generated Task Manager
Coding: Compile & Run
Beyond full-stack apps, I tested basic coding competence with four Python challenges and a React component task.
| Task | E4B | E2B |
|---|---|---|
| Python: FizzBuzz | Pass | Pass |
| Python: Binary Search | Pass | Pass |
| Python: Linked List Reversal | Pass | Pass |
| Python: Async HTTP Fetch | Pass | Pass |
| React: Interactive Component | Pass | Fail |
Both models handle standard Python competently — all 4/4 tasks passed for each. The difference shows on more complex React generation, where E4B succeeds and E2B stumbles. This is consistent with the full-stack app results above.
Agentic Multi-Step Reasoning
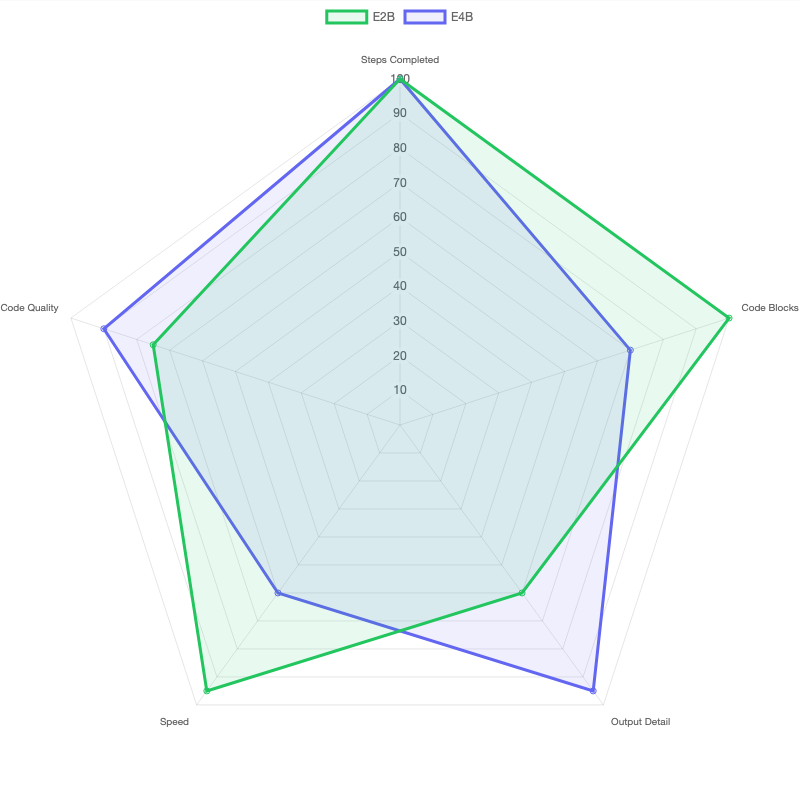
I tested both E4B and E2B on a 6-step sequential reasoning task that requires maintaining context across steps, referring back to earlier results, and making decisions based on accumulated information.
| Model | Steps Completed | Context Maintained? |
|---|---|---|
| E4B | 6/6 | Yes |
| E2B | 6/6 | Yes |
Both models aced the agentic task. They maintained context across all six steps, correctly referenced earlier outputs, and produced coherent final results. This is a strong showing for models this small — agentic behavior usually requires much larger parameter counts.
The KV Cache Elephant in the Room
I want to flag something I did not encounter in my testing but that the community has been vocal about. Multiple reports on r/LocalLLaMA describe KV cache issues with the Gemma 4 models, particularly:
- Memory spikes during long conversations as KV cache grows
- Sudden quality degradation after the context window fills up
- OOM crashes on 24GB machines with the 26B model under sustained load
“Gemma4 E4B works great for the first 2-3K tokens, then starts repeating itself. Clearing context fixes it.”
— r/LocalLLaMA user report
My benchmarks used relatively short, self-contained prompts, so I didn’t hit these limits. If you plan to use these models for extended conversations or agents with long context, keep an eye on KV cache behavior and be ready to manage context window size manually.
Official Benchmarks
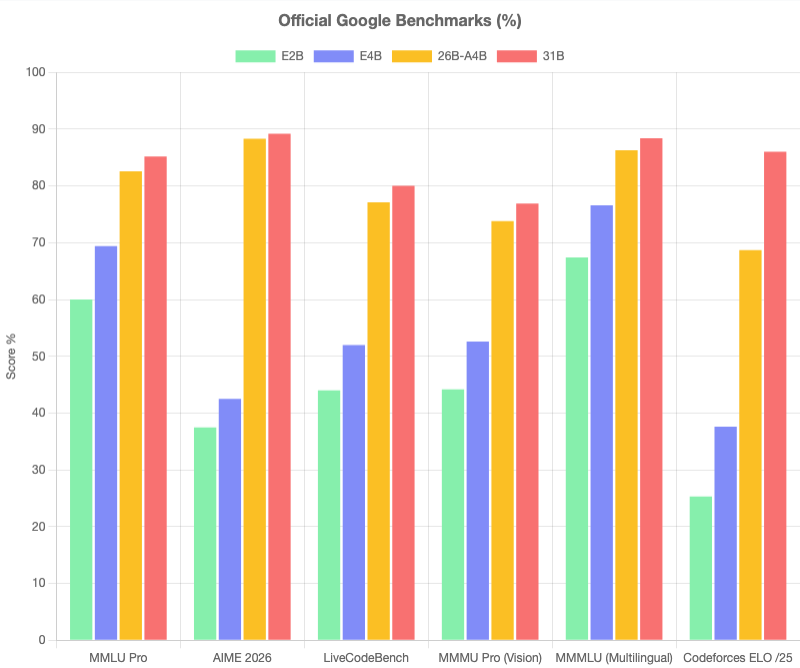
Google’s official numbers paint a strong picture for the entire family. On standard benchmarks (MMLU, HumanEval, GSM8K), the Gemma 4 models punch well above their weight class:
- E4B outperforms many 7B-class models on reasoning and code generation
- E2B is competitive with models 3-4x its size on text tasks
- 26B-A4B matches some 30B+ dense models while only activating 4B parameters per token
The official numbers align with what I saw in practice: these models are remarkably capable for their size. The question is always whether they run well on your hardware, and that’s what this benchmark answers.
Final Verdict
| Model | Score | Best For | Avoid If |
|---|---|---|---|
| E4B | 8.5/10 | Audio ASR, image tasks, app generation, coding | You need maximum speed above all else |
| E2B | 7/10 | Fast text generation, basic coding, simple image tasks | You need audio, complex code gen, or React apps |
| 26B-A4B | 2/10 | Nothing practical on 24GB | You have less than 48GB RAM |
Gemma 4 E4B is the clear winner for local use on 24GB hardware. It delivers genuine multimodal capability — audio, images, and code — at a speed that feels interactive. The jump from E2B to E4B is not incremental; it’s categorical, especially on audio and complex generation tasks.
E2B remains useful as a fast text assistant and for lightweight image tasks, but its audio capabilities are essentially non-functional and its code generation falls apart on anything beyond single-file scripts.
The 26B is a tease. On paper it should be the best of both worlds — MoE efficiency with large-model quality. In practice, 24GB is not enough to run it comfortably. Wait for better quantization or get more RAM.
The 31B was not tested — it simply does not fit in 24GB with any room to actually run.
Quick Start: Run Gemma 4 Locally in 60 Seconds
Install Ollama
# macOS
brew install ollama
# Or download from https://ollama.com
ollama servePull and Run E4B (Recommended)
# Pull the model (~2.5GB)
ollama pull gemma4-e4b
# Run interactively
ollama run gemma4-e4b
# Or via API
curl http://localhost:11434/api/generate \
-d '{"model": "gemma4-e4b", "prompt": "Hello!"}'Pull E2B (For Speed)
# Pull the smaller model (~1.5GB)
ollama pull gemma4-e2b
# Run it
ollama run gemma4-e2bAudio Input (E4B)
# Transcribe audio via API
curl http://localhost:11434/api/generate \
-d '{
"model": "gemma4-e4b",
"prompt": "Transcribe this audio",
"audio": ["'$(base64 -i audio.wav)'"]
}'Image Input
# Describe an image
ollama run gemma4-e4b "Describe this image" --images photo.jpg# Quick reference
# E4B: Best overall, 57 tok/s, audio+image+code
# E2B: Fastest, 95 tok/s, text+basic image only
# 26B: Skip on 24GB, wait for better quantCan’t Run 26B/31B Locally? Use Google AI Studio (Free)
The 26B and 31B models are too large for 24GB RAM locally. But Google hosts them for free via the Gemini API. No GPU needed — just an API key.
Free Tier Rate Limits
Gemma 4 26B: 15 RPM (requests/minute), 1,500 TPM (tokens/minute)
Gemma 4 31B: 15 RPM, unlimited TPM
Get your free key at aistudio.google.com/apikey
API Benchmark Results
Same prompts as local tests, run via the Gemini API with thinking mode enabled for reasoning tasks:
| Test | 26B-A4B | 31B |
|---|---|---|
| Fibonacci (Python) | 6.2s — correct | 10.4s — correct |
| Sieve of Eratosthenes | 9.8s — correct | 12.0s — correct |
| React Todo (TSX) | 33.1s — complete | 26.8s — complete |
| FastAPI CRUD | 34.9s — complete | 31.5s — complete |
| Spanish translation | 14.1s — natural | 17.9s — natural |
| Japanese translation | 22.2s — multiple forms | 27.7s — multiple forms |
| Arabic translation | 18.1s — correct | 16.8s — correct |
| Sum of 100 primes (thinking) | 60.8s — 24,133 correct | 79.3s — correct |
| Logic puzzle | 5.5s — correct | 5.2s — correct |
| Debug merge_sorted | 33.0s — found all 3 bugs | 26.3s — found all bugs |
Quality verdict: Both cloud models produce noticeably better output than E4B — more detailed explanations, multiple translation variants, stronger reasoning. The 31B model is slightly more concise while 26B is more verbose. Both found all bugs in the debug test, where E4B also succeeded locally.
Quick Start: Gemma 4 via API
export GEMINI_API_KEY="your-free-key-here"
# Gemma 4 31B with thinking mode
curl -X POST \
-H "Content-Type: application/json" \
"https://generativelanguage.googleapis.com/v1beta/models/gemma-4-31b-it:generateContent?key=$GEMINI_API_KEY" \
-d '{
"contents": [{"role": "user", "parts": [{"text": "Your prompt here"}]}],
"generationConfig": {
"thinkingConfig": {"thinkingLevel": "HIGH"}
}
}'Complete Comparison: Local vs Cloud
| Model | Where | Speed | Cost | Quality |
|---|---|---|---|---|
| E2B | Local (Ollama) | 95 tok/s | Free | 7/10 |
| E4B | Local (Ollama) | 57 tok/s | Free | 8.5/10 |
| 26B-A4B | Google AI Studio | ~21s/req | Free (15 RPM) | 9/10 |
| 31B | Google AI Studio | ~20s/req | Free (15 RPM) | 9.5/10 |
| E4B + 31B | Hybrid | Best of both | Free | Optimal |
Recommended setup: Use E4B locally for fast iteration (57 tok/s, instant, private), then validate complex reasoning/coding with 31B via the free API. Best of both worlds.
Your MacBook just became a multimodal AI workstation. Local for speed, cloud for power. All free.
██████╗ ███████╗███╗ ███╗███╗ ███╗ █████╗ ██╗ ██╗
██╔════╝ ██╔════╝████╗ ████║████╗ ████║██╔══██╗██║ ██║
██║ ███╗█████╗ ██╔████╔██║██╔████╔██║███████║███████║
██║ ██║██╔══╝ ██║╚██╔╝██║██║╚██╔╝██║██╔══██║╚════██║
╚██████╔╝███████╗██║ ╚═╝ ██║██║ ╚═╝ ██║██║ ██║ ██║
╚═════╝ ╚══════╝╚═╝ ╚═╝╚═╝ ╚═╝╚═╝ ╚═╝ ╚═╝
L O C A L • M U L T I M O D A L • F A S T